Le machine learning en apprentissage fédéré est au cœur d’une révolution technologique qui conjugue puissance algorithmique et respect de la confidentialité des données. Alors que les entreprises cherchent de plus en plus à exploiter les données distribuées sans jamais centraliser des informations sensibles, l’apprentissage fédéré s’impose comme une solution innovante. Cette approche, qui favorise la collaboration entre machines tout en maintenant la sécurité et la confidentialité des utilisateurs, ouvre la voie à des modèles décentralisés performants adaptés au contexte de l’intelligence artificielle moderne.
Dans un monde où la protection des données personnelles est devenue une priorité, comprendre les mécanismes du machine learning appliqués à l’apprentissage fédéré permet d’appréhender les enjeux liés à la sécurité des données. Que ce soit dans l’industrie, la santé ou les services financiers, les applications industrielles de ces technologies sont prometteuses et offrent des leviers puissants pour une innovation responsable. Cette exploration des principes fondamentaux et des cas d’usage concrets révèle comment l’apprentissage fédéré façonne l’avenir de l’intelligence artificielle.
Les principes fondamentaux du machine learning en apprentissage fédéré
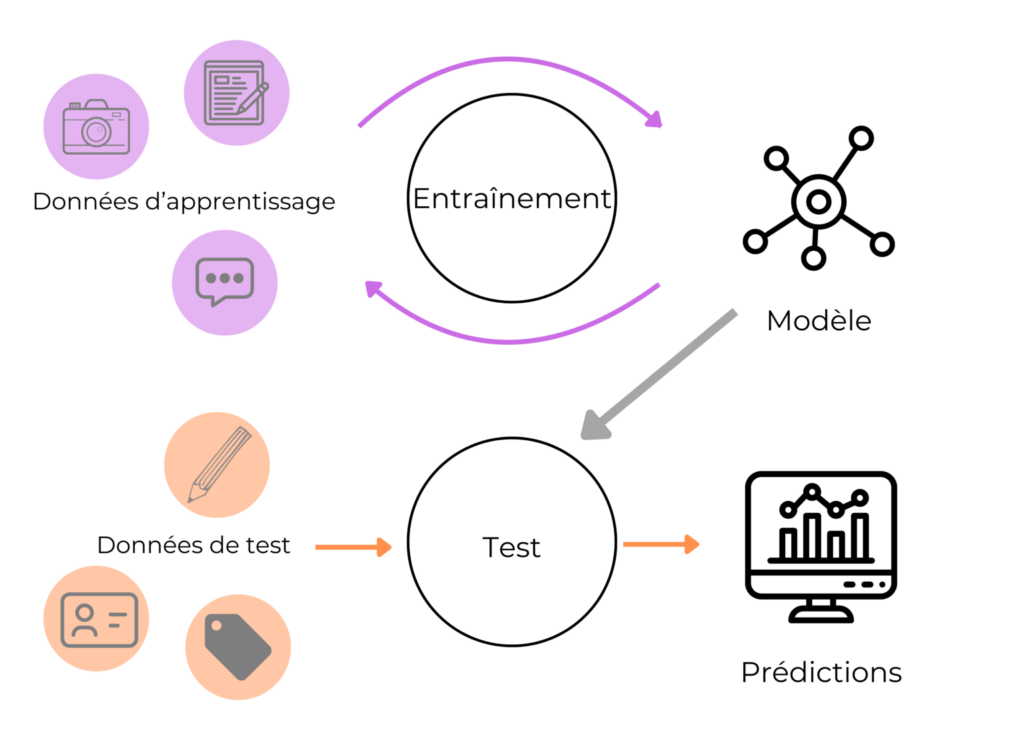
L’apprentissage fédéré constitue une méthodologie de machine learning où les modèles sont entraînés directement sur des appareils décentralisés, tels que des smartphones, des objets connectés ou des serveurs distants. Contrairement aux approches traditionnelles qui centralisent les données sur un unique serveur, cette technique permet aux données de rester sur leur source, minimisant ainsi les risques liés à la fuite ou au piratage de données sensibles. Cette structure conservant les données localement rend la confidentialité intrinsèquement plus robuste.
Concrètement, chaque appareil utilise ses données propres pour entraîner un modèle localement, puis envoie uniquement les mises à jour de ce modèle à un serveur centralisateur qui agrège ces contributions. Ce procédé assure que les données personnelles ne circulent pas, hormis ces ajustements du modèle. Le serveur agrège donc ces informations partielles pour reconstruire un modèle global plus performant.
Ce fonctionnement repose sur plusieurs concepts clés :
- Décentralisation des données : les données ne quittent jamais leur environnement d’origine, évitant ainsi la collecte massive souvent problématique.
- Agrégation des modèles : au lieu de transmettre les données elles-mêmes, on transmet les paramètres du modèle qui sont compilés en un modèle global.
- Confidentialité des données : des protocoles complémentaires peuvent être intégrés, tels que le chiffrement homomorphe ou l’anonymisation, pour renforcer la sécurité globale.
La robustesse des algorithmes employés dans ce cadre est essentielle, car ils doivent comporter des mécanismes de tolérance aux données non identiques ou distribuées de manière hétérogène chez les différents participants. Les techniques statistiques et d’optimisation évoluées jouent ici un rôle majeur pour garantir la convergence effective du modèle. Cette dynamique illustre notamment comment l’intelligence artificielle s’adapte aux contraintes du monde réel, où la diversité des sources de données reste un défi majeur.
Pour approfondir ces notions, il est utile de consulter des ressources spécialisées comme cette analyse détaillée sur le machine learning fédéré, qui éclaire les mécanismes sous-jacents et les enjeux contemporains.
Les avantages de l’apprentissage fédéré dans la protection et la sécurité des données
Dans un contexte où les violations de données sont devenues monnaie courante, l’apprentissage fédéré offre une avancée significative grâce à son modèle intrinsèquement sécurisé. Les données distribuées donnent ainsi lieu à un apprentissage sans déplacement des informations personnelles, ce qui complète parfaitement les préoccupations croissantes en matière de cybersécurité. Cette méthode garantit que les données restent stockées sur des dispositifs locaux, limitant considérablement les risques d’exposition lors des transferts.
Un autre avantage considérable est la possibilité d’assurer la conformité aux réglementations strictes sur la protection des données, telles que le RGPD en Europe. En ne transférant que les modèles au lieu des données brutes, les entreprises évitent les complications juridiques liées à la collecte et à l’utilisation massive des informations personnelles.
La sécurité des données est également renforcée par la capacité à implémenter des algorithmes spécifiques, comme :
- Le chiffrement différentiel : technique qui introduit un bruit contrôlé dans les paramètres transmis pour préserver la confidentialité individuelle des contributions.
- Les protocoles cryptographiques de sécurité multi-parties : qui permettent des calculs collaboratifs sans jamais divulguer les données privées.
- L’authentification renforcée : limitant l’accès aux mises à jour des modèles aux seuls participants légitimes.
Cela fait de l’apprentissage fédéré un cadre sain à la fois pour les développeurs d’algorithmes et pour les utilisateurs finaux soucieux de la confidentialité. De nombreuses industries commencent à intégrer ces modèles pour booster leurs performances tout en répondant aux exigences strictes en matière de protection des données.
La prise en compte du facteur humain dans cette collaboration entre machines est également clé. On assiste à une émergence de plateformes où les utilisateurs sont informés des usages et peuvent choisir leur niveau d’implication, renforçant ainsi la confiance dans le système.

Exemples concrets d’applications industrielles basées sur l’apprentissage fédéré
Le déploiement de l’apprentissage fédéré dans le secteur industriel illustre parfaitement comment cette technique révolutionne les processus décisionnels. Plusieurs entreprises adoptent ce paradigme pour traiter des masses colossales de données éparses tout en respectant la sécurité des informations.
Un exemple frappant concerne l’industrie automobile, où les véhicules connectés collectent d’innombrables données de conduite. Grâce à des modèles décentralisés, chaque véhicule peut contribuer à améliorer un système global de détection des anomalies ou d’optimisation du pilotage, sans jamais envoyer ses données brutes vers le cloud. Ce procédé permet non seulement de limiter les vulnérabilités en matière de cybersécurité, mais aussi d’affiner en continu les modèles grâce aux retours variés de milliers d’utilisateurs.
De même, le secteur de la santé bénéficie largement de l’apprentissage fédéré. Les hôpitaux et cliniques utilisent des modèles d’intelligence artificielle pour diagnostiquer et anticiper des maladies, en combinant les données cliniques disséminées dans différents établissements. Là encore, l’apprentissage fédéré assure une collaboration entre machines tout en préservant la confidentialité des données patient, une exigence cruciale.
Voici une liste des domaines industriels majeurs où l’apprentissage fédéré fait une différence palpable :
- Automobile connectée et véhicules autonomes
- Santé et diagnostics médicaux
- Finance et détection des fraudes
- Énergie et gestion intelligente des réseaux
- Télécommunications et optimisation de services réseaux
Par ailleurs, les applications du machine learning en apprentissage continu s’harmonisent parfaitement avec les principes de l’apprentissage fédéré, créant ainsi un système agile capable de s’adapter aux évolutions rapides du marché et des données.
Tableau comparatif des méthodes d’apprentissage réparti dans l’industrie
| Méthode | Avantages | Inconvénients | Exemples d’applications |
|---|---|---|---|
| Apprentissage centralisé | Performance maximale sur données centralisées | Risque élevé de fuite de données, coût élevé de transfert | Analyse de données bancaires, services en ligne |
| Apprentissage fédéré | Respect de la confidentialité, meilleure sécurité, adaptation locale | Complexité algorithmique, latence réseau possible | Automobile connectée, santé, télécommunications |
| Apprentissage fédéré avec chiffrement | Confidentialité maximale, haute sécurité | Besoin de ressources computationnelles importantes | Applications sensibles en finance et santé |
Les défis technologiques et éthiques liés à l’apprentissage fédéré en intelligence artificielle
Si les innovations autour du machine learning en apprentissage fédéré s’avèrent prometteuses, elles ne sont pas dénuées de défis importants. La complexité des algorithmes et la nécessité de gérer des données distribuées rendent les systèmes plus difficiles à concevoir et à maintenir. L’hétérogénéité des sources de données, avec des quantités et qualités différentes, complique la convergence des modèles globaux, ce qui peut ralentir leur utilité.
Les enjeux éthiques prennent également une place grandissante. Même si les données restent sur leurs appareils respectifs, le tri et l’agrégation en un modèle central nécessitent une vigilance constante pour éviter les biais discriminatoires ou des utilisations malveillantes. La transparence des algorithmes devient un impératif pour garantir que les décisions prises par ces systèmes automatisés soient justes et explicables.
Un point crucial demeure le contrôle des utilisateurs sur leurs propres données. En 2026, les initiatives visant à intégrer une gouvernance partagée des données se multiplient, offrant aux individus une meilleure visibilité et pouvoir décisionnel. L’apprentissage fédéré peut ainsi évoluer vers un modèle démocratique de gestion des données, garantissant un respect accru des droits fondamentaux.
Pour approfondir l’aspect éthique et technologique, la lecture de cette contribution sur la programmation d’événements normands alliant technologie et innovation apporte également une perspective locale enrichissante.
Perspectives futures et innovations attendues dans le domaine de l’apprentissage fédéré
À mesure que les infrastructures matérielles et les protocoles cryptographiques progressent, les perspectives d’évolution du machine learning en apprentissage fédéré s’étendent. Le développement de modèles toujours plus légers et efficaces permettra de déployer ces techniques dans des environnements encore plus variés et exigeants.
Des efforts sont mis en œuvre pour optimiser les algorithmes afin de réduire la consommation énergétique et la latence réseau, deux contraintes qui limitent actuellement l’adoption généralisée à grande échelle. Par ailleurs, la synergique avec d’autres paradigmes comme l’apprentissage profond ou l’intelligence artificielle embarquée se traduit par des performances améliorées sur des cas pratiques réels.
En plus de répondre aux besoins industriels croissants, l’apprentissage fédéré ouvre la voie à de nouvelles applications qui étaient jusque-là limitées par des problématiques de confidentialité ou de partage de données. Dans un avenir proche, on peut envisager :
- Une intégration renforcée dans les objets connectés domestiques et professionnels
- Une collaboration inter-entreprises facilitée pour la recherche et développement
- Une amélioration des systèmes de recommandation et personnalisation sans exposition des données utilisateurs
- Des outils avancés pour la gestion sécurisée et intelligente des données critiques
L’essor de ces technologies dans les années à venir contribuera indéniablement à façonner un environnement numérique plus sûr et plus performant. Le horizon s’annonce ainsi porteur d’innovations où la maîtrise des données distribuées devient un enjeu central.
Qu’est-ce que l’apprentissage fédéré ?
L’apprentissage fédéré est une méthode de machine learning permettant d’entraîner des modèles directement sur des appareils locaux sans transférer les données brutes, assurant ainsi la confidentialité des informations.
Quels sont les principaux avantages de l’apprentissage fédéré ?
Il garantit une meilleure sécurité des données, respecte la confidentialité des utilisateurs, réduit les risques de fuite d’informations et assure une conformité aux réglementations comme le RGPD.
Quels secteurs bénéficient le plus de l’apprentissage fédéré ?
Les industries comme l’automobile connectée, la santé, la finance, l’énergie ou les télécommunications exploitent pleinement les avantages des modèles décentralisés et de la collaboration entre machines.
Quels sont les défis techniques majeurs ?
Ils incluent la gestion de données hétérogènes, la complexité algorithmique accrue, la latence réseau, ainsi que la prévention des biais et la transparence algorithmique.
Comment l’apprentissage fédéré contribue-t-il à la protection de la vie privée ?
En conservant les données sur les dispositifs locaux et en ne partageant que les mises à jour modélisées, il minimise la circulation des informations sensibles.