À l’intersection de l’intelligence artificielle et des sciences du comportement, l’apprentissage par renforcement s’impose comme une branche innovante du machine learning. Son originalité réside dans la capacité des agents intelligents à apprendre par essais et erreurs, en interagissant avec un environnement dynamique pour maximiser une récompense cumulative. Ce mécanisme rappelle un peu la nature humaine, où chaque décision prise influence les résultats futurs, façonnant ainsi une politique optimale. Dès lors, comprendre les fondements de cet apprentissage demande une plongée au cœur des concepts clés tels que l’exploration, l’exploitation, les politiques d’action, et les fonctionnements algorithmiques comme le Q-learning. Ce paradigme ouvre la voie à des applications aussi variées que la robotique autonome, les jeux vidéo, la finance ou encore la gestion énergétique.
Le fonctionnement de l’apprentissage par renforcement repose sur un équilibre subtil entre exploration — découvrir de nouvelles stratégies — et exploitation — tirer profit des connaissances acquises. L’agent intelligent, placé dans un environnement souvent complexe et incertain, doit apprendre à adapter sa politique pour maximiser la valeur d’état, c’est-à-dire les bénéfices attendus de chaque situation rencontrée. L’efficacité de ce processus repose notamment sur l’utilisation précise des notions mathématiques et statistiques, mais aussi sur des algorithmes capables de s’adapter continuellement aux interactions en temps réel avec l’environnement. Cette synergie entre théorie et pratique justifie pleinement l’engouement actuel pour ce domaine en constante évolution.
Les bases fondamentales de l’apprentissage par renforcement en machine learning
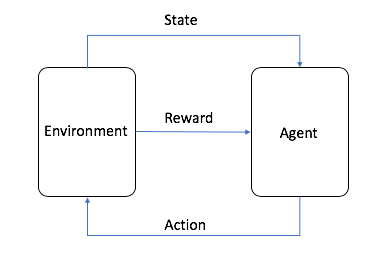
Le machine learning repose sur diverses approches, et l’apprentissage par renforcement en est une qui se distingue par son modèle d’apprentissage centré sur l’interaction avec l’environnement. Ici, l’agent intelligent — que ce soit un robot, un logiciel ou un système autonome — agit dans un environnement donné et reçoit en retour des informations sous forme de récompenses. L’objectif fondamental est de maximiser cette récompense au fil du temps, ce qui implique une modification et une amélioration continue de la politique de prise de décision.
Une politique, au cœur de cet apprentissage, est une fonction qui associe à chaque état de l’environnement une action. Cela nécessite que l’agent analyse la situation dans laquelle il se trouve pour choisir la meilleure réponse possible. Pour ce faire, l’agent cherche à estimer la valeur d’état, qui reflète la somme des récompenses futures attendues à partir d’un état donné. Cette évaluation est cruciale car elle guide l’agent sur quelles actions privilégier, en tenant compte non seulement de la récompense immédiate mais aussi des bénéfices à long terme.
Dans ce contexte, la différence entre exploration et exploitation devient primordiale. L’exploration consiste à tester des actions qui n’ont pas encore été suffisamment évaluées afin d’acquérir de nouvelles connaissances sur l’environnement. À l’inverse, l’exploitation privilégie les actions qui ont déjà montré leur efficacité pour maximiser la récompense reçue. Trouver un juste équilibre entre ces deux stratégies est essentiel pour optimiser l’apprentissage et éviter de rester coincé dans des schémas d’actions sous-optimaux.
Ce mode d’apprentissage différencie l’apprentissage par renforcement d’autres formes du machine learning, comme l’apprentissage supervisé où un modèle est entraîné à partir d’exemples annotés. Ici, aucune donnée étiquetée n’est fournie, seule la relation agent-environnement guide l’optimisation. C’est un système auto-adaptatif qui procède par essais successifs, ajustant sa politique au gré des résultats obtenus. Par exemple, un robot explorant un terrain inconnu devra élaborer sa politique en fonction des reconnaissances qu’il fait et des récompenses qu’il génère (comme avancer sans tomber).

Les algorithmes clés : Q-learning et autres méthodes pour optimiser l’apprentissage par renforcement
Au cœur de l’efficacité du machine learning en apprentissage par renforcement se trouvent des algorithmes puissants. Le Q-learning, l’un des plus connus, incarne un paradigme d’apprentissage hors politique (off-policy). Son principe est simple en apparence : estimer une fonction appelée Q, qui, pour chaque paire état-action, donne une évaluation de la « qualité » de choisir une action spécifique dans un état précis. Cette fonction Q se met à jour au fur et à mesure des interactions, permettant à l’agent de construire une stratégie optimale.
La mise à jour de la fonction Q repose sur la formule de Bellman, qui intègre la récompense immédiate ainsi que la meilleure valeur attendue pour le prochain état. Concrètement, la fonction Q est recalculée à chaque étape grâce à l’équilibre entre l’ancienne estimation et les nouvelles informations apportées par une interaction récente. Cette dynamique permet au système d’apprendre de manière autonome et adaptative, ce qui est indispensable dans les environnements imprévisibles.
Outre le Q-learning, d’autres méthodes méritent une attention particulière, notamment le SARSA, qui est un algorithme on-policy. Contrairement au Q-learning, SARSA met à jour sa fonction Q en fonction de la politique effectivement suivie par l’agent, ce qui le rend particulièrement pertinent pour des environnements où la politique évolue rapidement ou est incertaine.
Un autre axe d’évolution repose sur les méthodes dites profondes, qui combinent apprentissage par renforcement et réseaux de neurones profonds (deep learning). L’objectif est de gérer des environnements à très haute dimensionnalité où les états ne peuvent pas être encodés simplement, comme dans la reconnaissance d’images ou le contrôle autonome de véhicules. Ces modèles avancés, comme Deep Q-Networks (DQN), exploitent la puissance du machine learning continu pour créer des agents intelligents capables de performances exceptionnelles dans des domaines complexes.
Pour résumer les principales caractéristiques des algorithmes en apprentissage par renforcement, voici un tableau comparatif qui souligne leurs spécificités :
| Algorithme | Type | Politique | Avantage principal | Inconvénient |
|---|---|---|---|---|
| Q-learning | Off-policy | Optimale possible | Convergence garantie dans certains cas | Peut être lent sur de grands espaces d’état |
| SARSA | On-policy | Adapte la politique réelle | Mieux adapté aux environnements dynamiques | Moins stable que Q-learning |
| DQN | Deep Reinforcement Learning | Approximée via réseau de neurones | Gestion d’états complexes | Nécessite beaucoup de données d’entraînement |
L’enjeu de l’équilibre entre exploration et exploitation dans l’apprentissage par renforcement
Un des challenges majeurs dans l’apprentissage par renforcement réside dans la gestion de la balance entre exploration et exploitation. Une stratégie trop axée sur l’exploitation pourra rapidement converger vers une politique sous-optimale, tandis qu’une exploration excessive ralentira l’apprentissage et diluera les gains à court terme. Le compromis efficace garantit une exploration suffisante pour découvrir de nouvelles opportunités sans négliger l’exploitation des connaissances déjà acquises.
Différentes approches ont été développées afin d’adresser ce dilemme. L’une des plus connues est la stratégie ε-greedy, où l’agent choisit aléatoirement une action (exploration) dans un faible pourcentage de cas ε, et dans le reste du temps il suit la politique optimale connue (exploitation). Ce paramètre ε peut être adapté dynamiquement, souvent diminué au fil du temps pour privilégier l’exploitation une fois que l’environnement est suffisamment exploré.
Au-delà, des méthodes plus évoluées comme Upper Confidence Bound (UCB) ou Thompson Sampling sont employées pour mieux cibler l’exploration, notamment dans des contextes où chaque interaction est coûteuse. Ces algorithmes utilisent des principes statistiques pour estimer la valeur d’une action non encore suffisamment testée en tenant compte de son incertitude, offrant ainsi un cadre plus rigoureux que le simple hasard.
Cette problématique d’équilibre est cruciale dans des applications concrètes. Par exemple, dans la gestion de réseau électrique, il s’agit d’adapter en temps réel la consommation et production d’énergie par un agent intelligent tout en apprenant constamment des nouvelles configurations. Un mauvais équilibre risquerait soit un gaspillage énergétique soit des coupures de service. L’apprentissage par renforcement, appuyé par des algorithmes adaptés, permet alors de moduler en continu la politique pour optimiser la performance.
Applications concrètes et implications futures du machine learning en apprentissage par renforcement
L’impact du machine learning en apprentissage par renforcement se manifeste dans diverses industries, offrant des perspectives nouvelles où les agents intelligents s’adaptent en temps réel à des environnements complexes. L’essor des systèmes autonomes, qu’il s’agisse de drones, de véhicules autonomes ou encore d’assistants virtuels, illustre parfaitement les bénéfices de cette approche.
Dans la finance, des agents développés grâce à ces techniques sont capables d’apprendre des stratégies d’investissement en observant le marché et en optimisant leurs positions pour maximiser la récompense, ici le profit. Ces systèmes doivent toutefois intégrer les risques inhérents à la volatilité et la modélisation incertaine, un défi qui motive constamment l’innovation algorithmique.
Le secteur du jeu vidéo a également profité de ces avancées, comme en témoigne l’évolution des intelligences artificielles dans des jeux de stratégie complexes. Ces IA apprennent à maîtriser des politiques gagnantes en naviguant dans des environnements où les états possibles sont extrêmement nombreux, grâce notamment à des méthodes d’apprentissage profond comme les réseaux neuronaux. Cette progression constante rapproche les machines de comportements stratégiques proches de ceux des humains, voire les dépasse parfois.
Enfin, on observe un fort intérêt pour l’apprentissage par renforcement dans la robotique. Un robot dans un contexte industriel ou domestique doit prendre des décisions en temps réel, ajustant sa politique en fonction des retours de l’environnement, tout en optimisant ses actions pour accomplir des tâches efficacement. La récompense guide alors ses comportements, qu’il s’agisse d’atteindre un objectif matériel ou d’interagir avec l’humain.
Une autre illustration locale et culturelle de l’importance de la Normandie dans l’innovation et la formation aux nouvelles technologies se retrouve dans les institutions qui proposent des ressources et des formations spécialisées. Pour en savoir plus à propos du machine learning continu et des apprentissages incrémentaux, il est recommandé de consulter les avancées développées sur cette plateforme spécialisée, contribuant à créer un écosystème fertile pour les technologies d’intelligence artificielle.
Les défis techniques et éthiques du machine learning par renforcement à l’horizon 2026
Malgré ses succès, le machine learning fondé sur l’apprentissage par renforcement soulève plusieurs défis techniques et éthiques considérables. Sur le plan technique, la complexité computationnelle reste une limite dans certains cas, notamment pour des environnements à très haute dimension ou lorsque les interactions sont nombreuses et longues. Trouver des moyens d’accélérer l’apprentissage tout en garantissant robustesse et convergence est un enjeu majeur pour les chercheurs.
Par ailleurs, la qualité de la récompense joue un rôle fondamental dans l’efficacité et la justesse de l’apprentissage. Une définition inappropriée ou biaisée de la récompense peut conduire l’agent à adopter des comportements non souhaités, ou à optimiser des objectifs uniquement apparents au détriment d’autres valeurs cruciales. Il s’agit donc de concevoir de manière rigoureuse les mécanismes de rétroaction pour éviter ces écueils.
Sur le plan éthique, le déploiement massif d’agents intelligents apprend dans des environnements où humains et machines coexistent soulève des questions sur la transparence, la responsabilité et le contrôle des décisions prises par des intelligences artificielles. Il devient urgent d’encadrer légalement les usages de ces technologies pour garantir la sécurité et le respect des droits.
On peut citer comme défi majeur l’intégration des systèmes d’apprentissage par renforcement dans des domaines sensibles tels que la santé, où les conséquences d’erreurs peuvent être dramatiques. La confiance accordée à ces agents intelligents nécessite des validations approfondies et des mécanismes d’audit continus. Il en va de même dans le domaine de la mobilité autonome, où chaque décision prise par un véhicule peut influencer directement la sécurité des usagers.
Pour approfondir la réflexion sur ces enjeux et découvrir le lien entre les nouvelles technologies et les dynamismes régionaux, le site Normandie Prestiges offre un éclairage pertinent sur l’innovation locale et ses retombées culturelles.
Qu’est-ce qu’un agent intelligent en apprentissage par renforcement ?
Un agent intelligent est un système autonome qui interagit avec son environnement, prend des décisions basées sur une politique, et apprend à maximiser la récompense obtenue au fil des interactions.
Quelle est la différence principale entre exploration et exploitation ?
L’exploration consiste à tester de nouvelles actions pour découvrir leur efficacité, tandis que l’exploitation privilégie les actions déjà connues pour maximiser la récompense immédiate.
Comment fonctionne le Q-learning ?
Le Q-learning estime la qualité des actions dans chaque état en mettant à jour une fonction Q à chaque interaction, grâce à la formule de Bellman, permettant à l’agent de construire progressivement une politique optimale.
Quels sont les défis éthiques liés à l’apprentissage par renforcement ?
Ils incluent la transparence des décisions, la responsabilité en cas d’erreurs, et la protection contre les comportements non souhaités induits par des récompenses mal définies.
Où trouver des ressources fiables pour approfondir le machine learning en Normandie ?
Le site Normandie Prestiges propose plusieurs articles et formations pertinentes, notamment sur l’apprentissage continu en machine learning et l’innovation régionale.