Face à l’évolution rapide de l’intelligence artificielle et à l’accroissement exponentiel des volumes de données générées, l’apprentissage fédéré s’impose comme une révolution dans le domaine du machine learning. Cette méthodologie novatrice s’appuie sur un principe fondamental : exploiter des données distribuées tout en préservant leur confidentialité, répondant ainsi aux enjeux cruciaux de protection et de sécurité informatique. Contrairement aux approches traditionnelles qui centralisent les données, l’apprentissage fédéré permet de former des modèles décentralisés grâce à une optimisation distribuée, favorisant une collaboration entre plusieurs entités sans échange direct des données sensibles. Cette approche suscite un intérêt croissant dans divers secteurs industriels où le respect de la vie privée est impératif. Entre défis technologiques et perspectives prometteuses, les mécanismes d’agrégation de modèles deviennent la colonne vertébrale de cette technique, offrant un compromis subtil entre performance et confidentialité.
Dans un monde où la donnée est devenue une ressource stratégique, la capacité à exploiter efficacement des sources éparpillées tout en respectant les contraintes réglementaires transforme en profondeur les modèles traditionnels du machine learning. L’apprentissage fédéré, en intégrant des algorithmes capables de fonctionner sur des architectures distribuées, illustre l’évolution d’une intelligence artificielle au service d’une industrie plus sécurisée et responsable. De la santé aux télécommunications, en passant par la finance, les applications industrielles ne cessent de démontrer le potentiel de cette technologie pour créer des systèmes plus intelligents tout en réduisant les risques liés à l’exposition des données personnelles. Ce changement de paradigme s’accompagne d’une réflexion approfondie sur les méthodes d’agrégation de modèles et sur l’optimisation des échanges entre les nœuds participant au réseau, pour garantir une efficience maximisée sans compromettre la confidentialité.
Fondements essentiels de l’apprentissage fédéré en machine learning
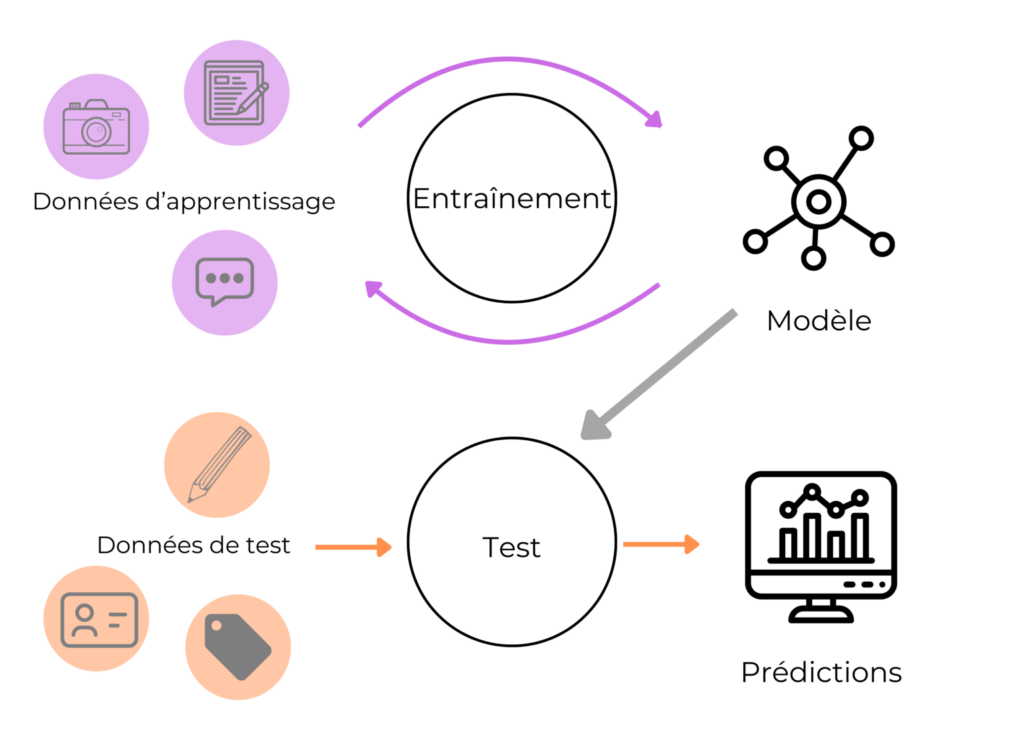
L’apprentissage fédéré s’enracine dans l’idée d’une intelligence artificielle collaborative où les données restent sur leurs sites d’origine. Ce principe vise à contourner les limites imposées par la gestion centralisée des données, notamment les risques liés à la confidentialité et à la sécurité informatique. Le concept repose sur un réseau de clients ou de nœuds détenant des données localisées, qui participent ensemble à la création d’un modèle global par une série d’itérations d’entraînement. Après avoir généré un modèle local sur chacun des clients, ces derniers transmettent uniquement leurs mises à jour au serveur central qui procède à une agrégation de modèles. Cette approche évite l’échange des données brutes et réduit considérablement les vulnérabilités aux fuites d’information.
Architecture décentralisée et optimisation distribuée
La structure décentralisée est la pierre angulaire du fonctionnement de l’apprentissage fédéré. Chaque participant exécute un entraînement local sur ses propres données sans jamais transférer celles-ci. L’agrégation de modèles, réalisée souvent via des algorithmes comme Federated Averaging, rassemble ces contributions pour ajuster un modèle partagé, tout en équilibrant les disparités entre les données distribuées. Cela nécessite une optimisation distribuée adaptée, où les techniques standards du machine learning sont repensées pour fonctionner efficacement dans un environnement non centralisé.
Par exemple, une firme de télécommunications peut rassembler des modèles pré-entraînés sur les données mobiles de clients détenues par différents opérateurs régionaux. Chaque opérateur entraîne localement un modèle reflétant ses propres spécificités, puis transmet uniquement des mises à jour combinables en un modèle global amélioré. Cette méthode réduit drastiquement les risques associés aux transferts de données personnelles tout en permettant une amélioration continue de la performance du modèle.
Enjeux de la confidentialité des données dans un environnement distribué
L’un des défis majeurs réside dans la garantie de la confidentialité des données au cours du processus d’apprentissage. Les techniques traditionnelles d’anonymisation ne suffisent pas toujours à protéger les informations sensibles. C’est pourquoi des mécanismes complémentaires, tels que le chiffrement homomorphique, l’obfuscation ou l’intégration de protocoles cryptographiques, sont souvent intégrés. Ces solutions s’inscrivent dans une logique de sécurité informatique robuste, essentielle quand les applications industrielles impliquent des données critiques, par exemple dans le secteur médical ou bancaire.
Ce paradigme vise à assurer que, même si des acteurs malveillants venaient à intercepter les communications, les informations confidentielles restent inaccessibles. L’apprentissage fédéré ouvre ainsi la voie à une intelligence artificielle respectueuse des régulations sur la protection des données, telles que le RGPD en Europe, tout en promouvant une dynamique collaborative entre différentes organisations.

Techniques d’agrégation de modèles au cœur de l’apprentissage fédéré
L’agrégation de modèles est un élément clé qui détermine la qualité et la robustesse du modèle fédéré. Il s’agit d’une étape où les mises à jour des modèles locaux sont combinées pour créer une nouvelle version du modèle global. Cette tâche est particulièrement délicate, car elle doit conjuguer efficacité, scalabilité et sécurité informatique. Le choix de la méthode d’agrégation impacte directement la capacité du système à gérer les données hétérogènes et les nœuds défaillants ou malveillants.
Principaux algorithmes et stratégies d’agrégation
Plusieurs algorithmes ont été développés pour répondre aux exigences spécifiques de l’apprentissage fédéré :
- Federated Averaging (FedAvg) : C’est la méthode la plus utilisée, qui moyenne les poids des modèles locaux selon la taille des données de chaque client.
- Weighted Aggregation : Prend en compte non seulement la taille mais aussi la qualité des données, attribuant plus de poids aux mises à jour provenant de datasets plus fiables.
- Secure Aggregation : Garantit une confidentialité accrue, notamment par des protocoles cryptographiques qui empêchent même le serveur central de voir les mises à jour individuelles.
- Outlier Detection : Identifie et neutralise les contributions aberrantes afin de renforcer la robustesse du modèle contre les attaques ou erreurs locales.
L’efficacité de ces techniques est souvent évaluée dans des contextes industriels où les données présentent des biais ou sont fortement déséquilibrées. La flexibilité dans l’adaptation des algorithmes d’agrégation permet aussi d’optimiser l’apprentissage sur des systèmes hétérogènes, renforçant la pertinence des modèles décentralisés.
Tableau comparatif des algorithmes d’agrégation en apprentissage fédéré
| Algorithme | Avantages | Inconvénients | Applications industrielles |
|---|---|---|---|
| Federated Averaging (FedAvg) | Simplicité, scalabilité, largement supporté | Moins robuste aux données hétérogènes | Télécommunications, IoT |
| Weighted Aggregation | Prise en compte qualité des données | Complexité accrue, nécessite une évaluation fine | Santé, finance |
| Secure Aggregation | Confidentialité renforcée | Surcoût computationnel | Banque, secteur public |
| Outlier Detection | Robustesse aux attaques et erreurs | Difficulté à détecter certains outliers | Industrie manufacturière, sécurité |
Applications industrielles majeures de l’apprentissage fédéré
Les applications industrielles de l’apprentissage fédéré sont plurielles et concernent des domaines où le traitement massif de données distribuées s’accompagne d’une exigence forte de confidentialité. La santé illustre bien cette dynamique : plusieurs hôpitaux peuvent collaborer pour entraîner un modèle capable de détecter des pathologies à partir d’images médicales sans pour autant partager les données des patients. Cette collaboration optimise la qualité des diagnostics tout en respectant les normes éthiques.
Exemple concret dans la santé et la finance
Dans le secteur financier, les banques bénéficient de modèles décentralisés pour détecter des fraudes sans compromettre les données sensibles de leurs clients. En évitant la centralisation, l’apprentissage fédéré limite le risque de fuite des données et permet d’améliorer les systèmes de détection en exploitant la richesse des données réparties. Ces usages sont d’autant plus essentiels dans un contexte où la cybercriminalité ne cesse d’évoluer, soulignant la nécessité d’une sécurité informatique renforcée couplée à des capacités d’analyse précises.
En automatisation industrielle, des capteurs disséminés sur une chaîne de production peuvent partager des mises à jour de modèles visant à optimiser la maintenance prédictive sans divulguer l’ensemble des données d’usine, protégeant ainsi les secrets industriels tout en réduisant les coûts liés aux pannes.
Perspectives et défis futurs pour le machine learning en apprentissage fédéré
Si l’apprentissage fédéré connaît un essor véritable, plusieurs défis techniques et organisationnels demeurent pour étendre son adoption. L’optimisation distribuée doit s’améliorer pour réduire les temps d’entraînement et le coût en ressources tout en garantissant une robustesse face aux défaillances de réseau ou aux attaques malveillantes. La sécurisation des échanges via des protocoles toujours plus performants sera également au centre des préoccupations.
Un horizon prometteur ouvre également la porte à des architectures hybrides mélangeant apprentissage fédéré et edge computing, permettant d’accroître l’autonomie des dispositifs tout en affinant la qualité de l’intelligence artificielle embarquée. Ces innovations faciliteront la généralisation de l’approche dans le secteur automobile, la domotique, ou encore les villes intelligentes.
Voici une liste des principaux axes de recherche et enjeux à venir :
- Amélioration des protocoles d’agrégation sécurisée pour minimiser les risques de fuite malgré la présence d’acteurs malveillants.
- Gestion plus fine de la diversité des données distribuées pour garantir l’équité et la précision des modèles dans des contextes à forte hétérogénéité.
- Réduction de la consommation énergétique liée aux multiples échanges entre nœuds pour limiter l’impact environnemental.
- Intégration avec les technologies émergentes telles que la blockchain pour renforcer la traçabilité et la confiance.
- Développement d’outils d’analyse et de visualisation adaptés à ces nouveaux modèles décentralisés pour faciliter leur adoption.
Ces pistes dessinent une feuille de route ambitieuse pour un machine learning plus éthique, respectueux des données et capable de répondre aux exigences complexes des applications industrielles contemporaines.
Qu’est-ce que l’apprentissage fédéré exactement ?
C’est une méthode de machine learning où les données restent sur leurs dispositifs d’origine et seuls les modèles entraînés localement sont partagés pour créer un modèle global, assurant ainsi la confidentialité.
Quels sont les avantages principaux de l’apprentissage fédéré ?
Il préserve la confidentialité des données, permet l’analyse de données distribuées et améliore la sécurité informatique en limitant les risques liés au transfert de données.
Dans quels secteurs industriels l’apprentissage fédéré est-il le plus utilisé ?
Les domaines de la santé, finance, télécommunications, et industrie manufacturière exploitent largement cette technologie pour renforcer la confidentialité et optimiser leurs modèles prédictifs.
Comment l’agrégation de modèles fonctionne-t-elle ?
Elle combine les mises à jour des modèles locaux en un modèle global via des algorithmes spécifiques, permettant d’améliorer la performance sans partager les données originales.
Quels sont les défis actuels de l’apprentissage fédéré ?
Ils incluent la gestion de la diversité des données, la sécurisation des échanges, la réduction de la consommation énergétique, et l’amélioration des protocoles d’agrégation.