Dans un monde où l’intelligence artificielle (IA) évolue à un rythme effréné, la capacité des systèmes à apprendre de manière continue devient un impératif majeur. Le continual learning, ou apprentissage continu, révolutionne le machine learning traditionnel en permettant aux modèles d’intégrer de nouvelles données sans perdre les acquis précédents. Cette approche répond à une problématique fondamentale : comment concevoir des modèles adaptatifs capables de s’ajuster aux nouveaux environnements ou aux données séquentielles, sans subir le fameux phénomène de catastrophic forgetting ? Alors que les systèmes classiques nécessitent souvent une réinitialisation complète lors de l’arrivée de nouvelles informations, les méthodes d’apprentissage continu proposent une adaptation dynamique et progressive. Cela ouvre des perspectives fascinantes, notamment dans des secteurs variés comme la robotique, la reconnaissance vocale, ou encore les applications médicales, où les contextes évoluent et les données arrivent de manière séquentielle, impose une mise à jour constante des algorithmes d’apprentissage. Comprendre les fondements du continual learning est ainsi essentiel pour saisir l’état actuel et futur du développement des intelligences artificielles les plus performantes.
Au cœur de cette révolution se trouvent des stratégies innovantes visant à maintenir une mémoire dynamique, limitant ainsi la perte d’informations antérieures tout en consolidant de nouvelles connaissances. Ces modèles adaptatifs incarnent une avancée majeure face aux limites du machine learning traditionnel. Cet article explicite en profondeur les mécanismes du continual learning : de ses principes de base, aux défis techniques, en passant par les principales architectures et algorithmes. De plus, des exemples concrets illustrent comment les IA d’aujourd’hui exploitent ces techniques pour gérer des flux constants d’informations. L’approche vers une machine intelligente capable d’apprendre de manière perpétuelle devient alors tangible, révélant tout le potentiel encore à dévoiler de l’apprentissage automatique dans tous les domaines du savoir et de l’innovation.
Comprendre le fonctionnement du machine learning dans un cadre d’apprentissage continu
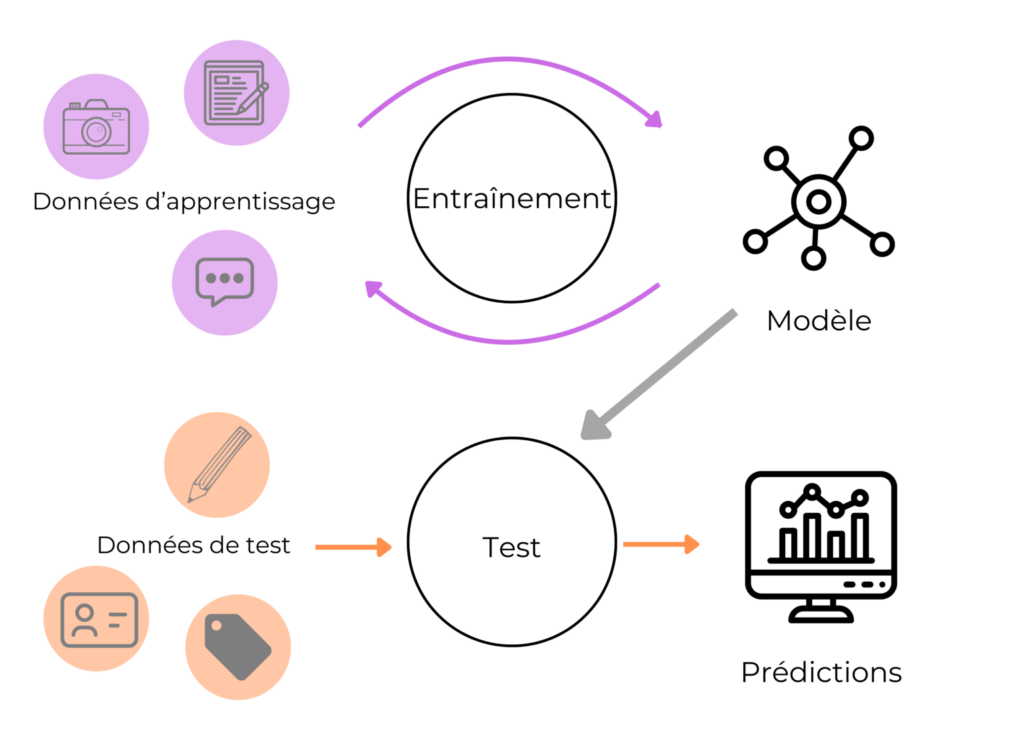
Le machine learning conventionnel repose généralement sur un ensemble fixe de données d’entraînement utilisé pour construire un modèle statique. Mais dans l’apprentissage continu, la nature même des données change, imposant aux systèmes de s’adapter sans repartir de zéro. Le continual learning se définit donc par l’intégration séquentielle de données nouvelles, incitant le modèle à évoluer et à conserver ses acquis. Il ne s’agit plus seulement de classifier ou prédire à partir d’un ensemble figé, mais d’assimiler sans cesse de nouveaux exemples issus de distributions changeantes.
Les modèles adaptatifs ainsi créés doivent surmonter le risque de catastrophic forgetting, une perte dramatique de la mémoire des données antérieures lors d’une mise à jour avec un nouveau lot. Par exemple, un système de reconnaissance faciale constamment entraîné avec des visages nouveaux pourrait oublier comment identifier des individus observés auparavant si aucune technique adéquate n’est appliquée. Ce phénomène reste l’un des principaux défis techniques dans le domaine. Pour y remédier, des mécanismes comme l’enregistrement sélectif de souvenirs anciens ou la régulation des modifications des paramètres du réseau sont employés.
Les algorithmes d’apprentissage utilisés doivent être capables de manipuler la mémoire dynamique et de prioriser certaines informations. Ainsi, les techniques comme la rétention partielle (replay), la consolidation progressive (regularisation), ou le transfert de connaissance (distillation) sont mises en œuvre selon les cas. Travailler avec des données séquentielles réclame également un ajustement constant des poids du modèle, pour maintenir une performance optimale sur l’ensemble des tâches passées et présentes.
Imaginons une entreprise déployant un assistant vocal évolutif. L’assistant doit apprendre des habitudes et préférences des utilisateurs au fil du temps, tout en ne perdant pas la capacité à comprendre des commandes classiques initiales. C’est grâce à l’apprentissage continu que ce système peut se renouveler sans perdre en fiabilité. La maîtrise de ces bases, tant théoriques que pratiques, est donc indispensable pour progresser efficacement dans le domaine.

Les méthodes principales employés en continual learning pour éviter le catastrophic forgetting
Le phénomène de catastrophic forgetting représente un obstacle de taille à l’efficacité des modèles en apprentissage continu. Plusieurs approches ont été développées pour limiter cet effet, chacune possédant ses atouts et limites propres. Comprendre ces méthodes, c’est d’abord appréhender leurs principes, afin de saisir comment elles permettent à une intelligence artificielle de conserver ses acquis tout en intégrant de nouvelles connaissances.
Mémoire dynamique et relecture d’anciens exemples (Replay)
Le replay consiste à conserver un sous-ensemble réduit d’anciens exemples, qui sont régulièrement rejoués lors des phases d’entraînement avec les nouvelles données. Cela permet au modèle de ne pas oublier les informations passées en les « réexposant ». Par exemple, dans le domaine de la vision par ordinateur, des images clés des anciennes classes peuvent être stockées pour être intégrées dans les sessions d’entraînement ultérieures. Cette méthode impose cependant une gestion judicieuse de la mémoire afin d’éviter une explosion des données stockées.
Régularisation des paramètres
La régularisation consiste à contraindre les modifications des paramètres du réseau de neurones lors de l’apprentissage des nouvelles données. Des techniques comme Elastic Weight Consolidation (EWC) attribuent une importance différente à chaque poids, protégeant ceux détenteurs d’informations plus critiques. Cette approche est particulièrement efficace lorsque les tâches successives présentent des différences modérées.
Distillation et transfert de connaissances
La distillation vise à transférer les connaissances d’un ancien modèle vers un nouveau, agissant comme un pont entre les générations successives de l’IA. Le nouveau modèle est entraîné non seulement sur les nouvelles données, mais également pour imiter les comportements prédictifs de son prédécesseur. Elle aide à préserver la mémoire des connaissances antérieures de manière fluide.
Voici un tableau présentant un résumé des principales méthodes employées et leurs caractéristiques :
| Méthode | Principe | Avantages | Limites |
|---|---|---|---|
| Replay | Réexposition d’anciens exemples | Réduit efficacement le forgetting | Nécessite stockage mémoire, potentiellement coûteux |
| Régularisation | Protection des poids importants | Peu gourmand en mémoire | Efficace surtout pour tâches similaires |
| Distillation | Transfert des prédictions du modèle ancien | Bonne préservation des connaissances | Complexité d’implémentation |
Développer une stratégie adaptée nécessite donc l’analyse fine des cas d’usage, la nature des données séquentielles, et les ressources disponibles. La combinaison de plusieurs approches s’avère souvent nécessaire pour maximiser les performances.
Applications concrètes de l’apprentissage continu en intelligence artificielle moderne
L’apprentissage continu en apprentissage automatique n’est pas une simple curiosité académique, mais devient un pilier de nombreuses applications modernes. Les modèles adaptatifs dotés de mémoire dynamique offrent une solution robuste face aux environnements changeants et aux contraintes de temps réel, notamment dans des secteurs où les données évoluent constamment.
Dans l’industrie automobile, les véhicules autonomes exploitent le continual learning pour actualiser leurs connaissances sur les comportements des conducteurs, les conditions routières, ou encore les infrastructures urbaines. Par exemple, l’arrivée de nouveaux panneaux de signalisation ou la modification des règles de circulation sont intégrées au modèle sans nécessiter un réapprentissage complet. Ainsi, la sécurité se voit renforcée.
Un autre exemple probant se trouve dans la cybersécurité où les algorithmes d’apprentissage doivent détecter de nouvelles formes de cyberattaques tout en conservant la capacité à identifier les menaces déjà connues. Grâce à l’apprentissage continu, ces systèmes s’adaptent à des données séquentielles très diverses, rendant la défense plus réactive face à des menaces en constante mutation.
Dans le domaine de la santé, les intelligences artificielles employées pour le diagnostic médical profitent aussi de cette approche. Un modèle peut intégrer progressivement des données issues de nouvelles pathologies ou d’études cliniques récentes afin d’améliorer la précision de ses prédictions. Cela illustre parfaitement la puissance de l’adaptation continue au service de domaines critiques.
- Véhicules autonomes intégrant nouvelles données topographiques
- Assistants vocaux personnalisés améliorant leur compréhension sur le temps
- Systèmes de surveillance adaptatifs en cybersécurité
- Modèles de diagnostic évolutifs en santé
- Applications financières anticipant les fluctuations de marché
Les défis restent cependant nombreux, notamment sur la gestion des volumes de données et la garantie d’une mémoire dynamique fidèle et efficace. Néanmoins, ces exemples démontrent que le continual learning est une révolution en marche, propulsant la fiabilité et la flexibilité des intelligences artificielles à un autre niveau.
Techniques avancées pour la mise à jour de modèles en machine learning continu
Mettre à jour un modèle dans un cadre d’apprentissage continu réclame bien plus que l’intégration brute de nouvelles données. La sophistication des algorithmes d’apprentissage, la gestion fine de la mémoire dynamique et la capacité à anticiper les conflits entre tâches successives sont des enjeux primordiaux. Plusieurs techniques avancées sont désormais utilisées pour optimiser cette transition.
La première consiste en une architecture modulaire dite « progressive networks » dans laquelle le modèle se compose de différents blocs spécialisés, évitant ainsi que l’apprentissage d’une nouvelle tâche n’interfère avec les précédentes. Ces modules peuvent être activés selon la tâche en cours, facilitant le maintien des performances antérieures tout en intégrant les nouveautés.
Ensuite, on retrouve les réseaux génératifs qui, au lieu de simplement stocker les données anciennes, génèrent des exemples synthétiques proches, utilisés pour la relecture lors des entraînements. Cette méthode réduit grandement les besoins en mémoire et permet au modèle de diversifier ses souvenirs.
Enfin, les techniques de meta-learning, où l’algorithme apprend à apprendre, prennent aussi une place prépondérante. Elles permettent au modèle de s’adapter plus rapidement aux nouvelles tâches en exploitant ses expériences passées, composant ainsi un apprentissage continu à la fois efficace et rapide.
Voici les principales techniques de mise à jour utilisées :
- Réseaux modulaires (progressive networks) – isolation et spécialisation par tâches
- Réseaux génératifs pour la synthèse des données historiques
- Meta-learning pour accélérer l’adaptation aux nouvelles données
- Regularisation avancée pour préserver la stabilité des paramètres
- Replay intelligent combiné à des techniques de pondération
Chacune de ces techniques agit comme un levier pour améliorer la robustesse et la durabilité des modèles adaptatifs. Leur implémentation dépend fortement de la nature des applications, des contraintes matérielles, et des objectifs de performance des systèmes. La recherche en continual learning s’emploie constamment à affiner ces méthodes pour dépasser les limites actuelles.
Évolution et enjeux futurs de l’apprentissage continu dans les systèmes intelligents
L’apprentissage continu ne cesse d’influencer le développement de l’intelligence artificielle, promettant des systèmes toujours plus intelligents, flexibles et autonomes. Cette discipline, encore jeune, est amenée à radicalement transformer la manière dont les IA interagissent avec le monde réel, en rendant possible une adaptation en temps réel aux évolutions et imprévus.
À l’horizon 2030, les modèles adaptatifs disposeront sans doute d’une mémoire encore plus dynamique et sélective, capable de gérer un volume colossal de données séquentielles avec peu ou pas de pertes. L’optimisation énergétique et la réduction de la complexité computationnelle seront également des axes majeurs, afin de pouvoir déployer ces approches sur des dispositifs embarqués ou connectés.
Les enjeux éthiques et de sécurité associés à ces évolutions sont eux aussi primordiaux. Assurer la transparence dans la mise à jour des modèles, garantir la confidentialité des données traitées, et prévenir les biais persistants dans l’apprentissage sont autant de défis à relever pour que cette technologie soit durablement bénéfique.
Un autre aspect critique est le développement d’algorithmes capables d’apprendre non seulement de nouvelles tâches, mais également de détecter automatiquement les changements dans les flux de données, activant des mises à jour de modèles de façon autonome. Cela correspond à la vision d’une intelligence artificielle véritablement interactive et proactive.
Pour conclure cette exploration, il faut garder en tête que le continual learning symbolise un pont fondamental entre la rigueur du machine learning et la nécessite constante de flexibilité dans un monde en perpétuelle mutation. Sa maîtrise constituera sans doute un avantage stratégique majeur pour toute organisation souhaitant exploiter pleinement le potentiel de l’intelligence artificielle.
Qu’est-ce que le catastrophic forgetting en apprentissage continu ?
Le catastrophic forgetting est un phénomène où un modèle d’apprentissage automatique oublie brusquement des connaissances précédemment acquises lorsqu’il est entraîné sur de nouvelles données, mettant en péril la stabilité des performances.
Comment les modèles adaptatifs gèrent-ils les données séquentielles ?
Ils utilisent des techniques telles que la mémoire dynamique, le replay sélectif, et des régularisations pour intégrer progressivement les nouvelles données tout en conservant les connaissances passées.
Quels sont les principaux défis du continual learning en 2026 ?
Les défis majeurs incluent la gestion optimale de la mémoire, la prévention du catastrophic forgetting, la limitation de la complexité computationnelle, ainsi que la garantie de la confidentialité et de l’éthique dans le traitement des données.
En quoi les techniques de distillation améliorent-elles l’apprentissage continu ?
La distillation permet de transférer les connaissances d’un ancien modèle vers un nouveau, facilitant ainsi la préservation des acquis tout en intégrant efficacement des nouveautés.
Quels secteurs bénéficient le plus de l’apprentissage continu ?
Des secteurs comme l’automobile autonome, la cybersécurité, la santé, les assistants virtuels, ou les finances voient des bénéfices significatifs grâce aux modèles capables d’adaptation continue.